According to industry reports, there will be an 800% increase in enterprise data, and about 80% of it will be unstructured data.
Enterprise data is growing rapidly and propagating due to the advent of cloud technologies and cloud collaboration, thereby making it very challenging to secure. The smart strategy is to first identify the data in your enterprise that is valuable, thus must be secured with additional steps above and beyond your standard enterprise security posture. Essentially separating the vital few from the trivial many.

Data Classification is the critical step that helps you identify high value content in your enterprise by categorizing your data into an agreed set of categories that are specific and meaningful to your enterprise. Data Classification drives multiple use cases such as data labelling, sensitive data identification, automating protection, compliance, security, access-control, data retention etc. With much dependent on this critical step it is useful to know the state of the art today on Data Classification, and the uses and limitations of these approaches. The three main means to classify data:
Enterprises rely on the end user to manually tag the document with the appropriate category and assign a sensitivity level of the document. When done right and at the time of document creation this is a very effective method because a person can apply their expert judgement and classify appropriately. For example, AIP (Azure Information Protector) has the capability to enable end users to classify documents as sensitive and can also limit access to them. This approach relies on a combination of end-user agents, centralized trigger rules and finally the end-user manually applying tags to documents and communications. End-user based classification has some limitations:
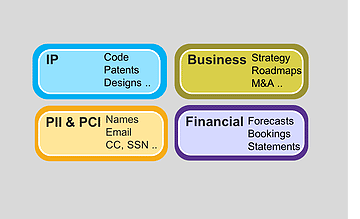
An example of comprehensive, effective Data Classification framework
A centralized policy-based data classification technique entails central rules that are then used to classify documents without the need for end user input. DLP (Data Loss Prevention) and CASB (Cloud Access Security Brokers) products generally have some policy based classification in place. An example policy could be to “Mark all documents that have the code word Sedona as sensitive”. This approach can easily tag documents that are identified by rules, taking the human element out, but it also has some limitations:
Organizations also classify data by identifying document sensitivity using the associated meta-data. Some examples of meta-data information are (a) the file folder in which the document is stored, (b) the role of the person that creates or accesses a document (c ) the title level or organization the person belongs to etc. An example of meta-data driven classification is any document that a company executive has access to is marked as sensitive. Or marking any document that is stored in the “Revenue Forecasts” folder is automatically marked as sensitive. The limitations of this approach are:
Data Classification when done right can be a foundational element to meaningful data security. Security leaders must factor both the capabilities and the limitations of these approaches when assessing the business risk posed by their current data classification strategy and continually assess the quality of their Data Classification efforts.